Works
Data Pipeline
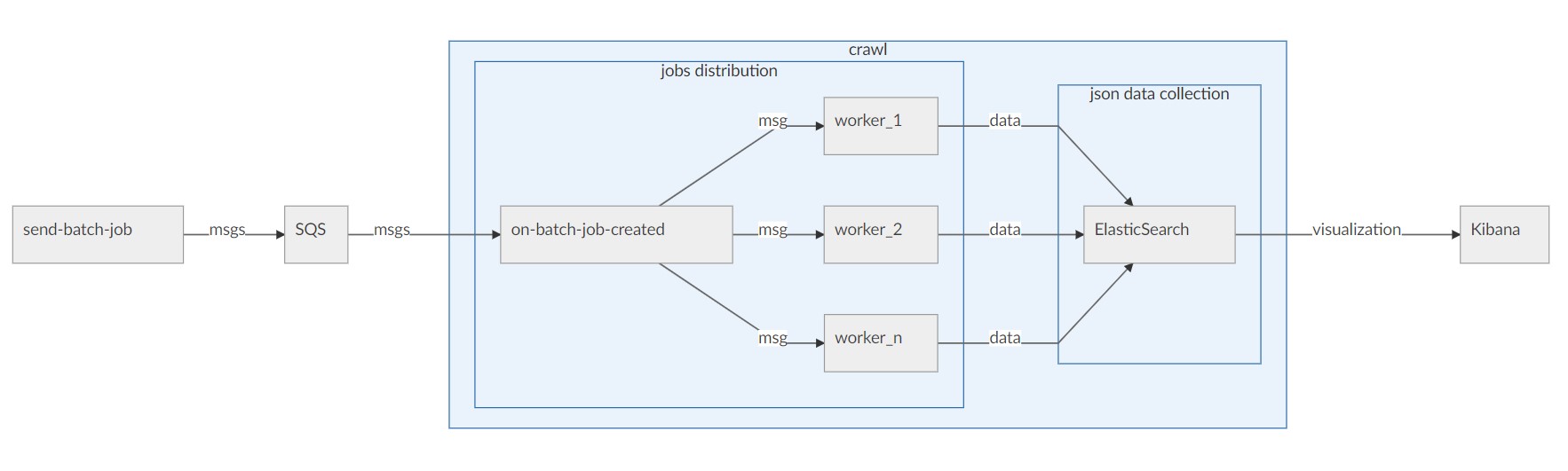
- 크롤러로 시작해서 데이터 축적의 필요성을 느껴 잡 스케쥴링을 통해 추출한 데이터를 ElasticSearch로 보내는 파이프라인을 구축했습니다.
-
깃허브 저장소는 아래와 같습니다.
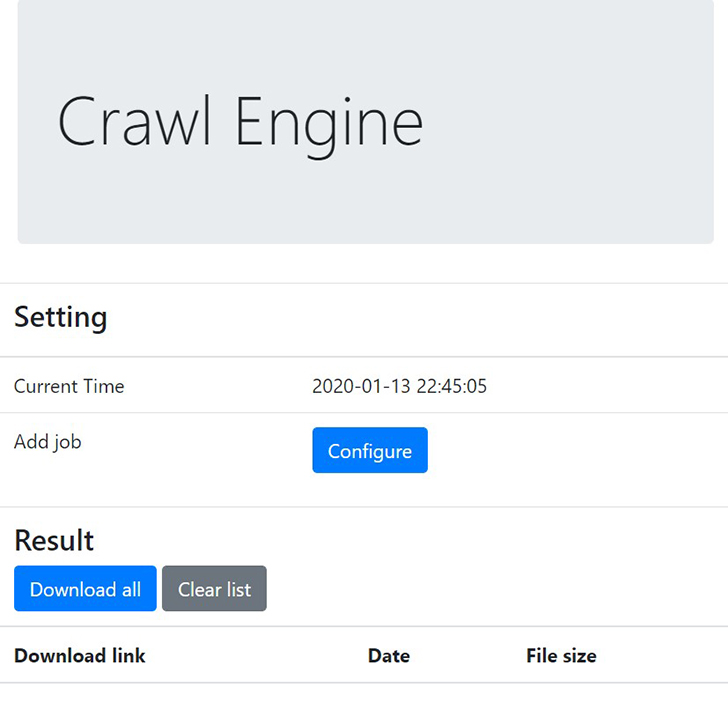
- pipeline-crawler: 크롤엔진 코드와 사용법에 관한 문서 저장소입니다.
- pipeline-lambdas: Serverless 프레임워크로 레이어된 Lambda 함수와 사용법에 관한 문서 저장소입니다.
- pipeline-elk: ELK스택으로 데이터를 넣고 빼는 기능과 사용법에 관한 문서 저장소입니다.
- pipeline-pipeline-detail: Lambda 함수부터 크롤엔진을 거쳐 ElasticSearch로 흐르는 워크플로우에 관한 문서 저장소입니다.
-
기술스택은 아래와 같습니다.
- pipeline-crawler: aws-sdk, express, moment, puppeteer, pug, socket.io, react
- pipeline-lambdas: aws lambda, aws sqs, aws-sdk, typescript, serverless
- 프로젝트 구조는 여기에서 확인할 수 있습니다.
- 크롤러 데모페이지는 여기에서 확인할 수 있습니다.
{kind=link}
{kind=link}
Training Log
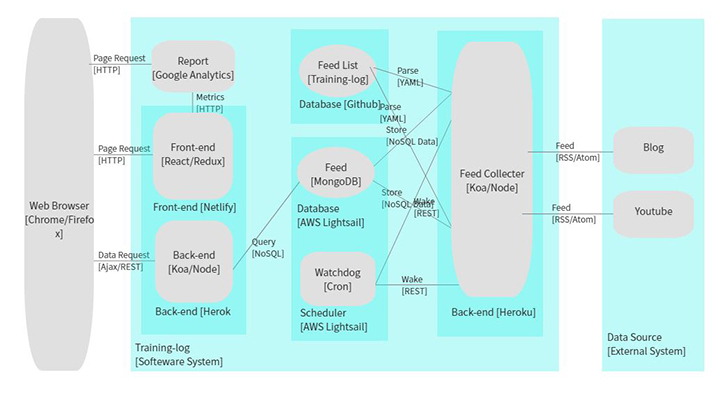
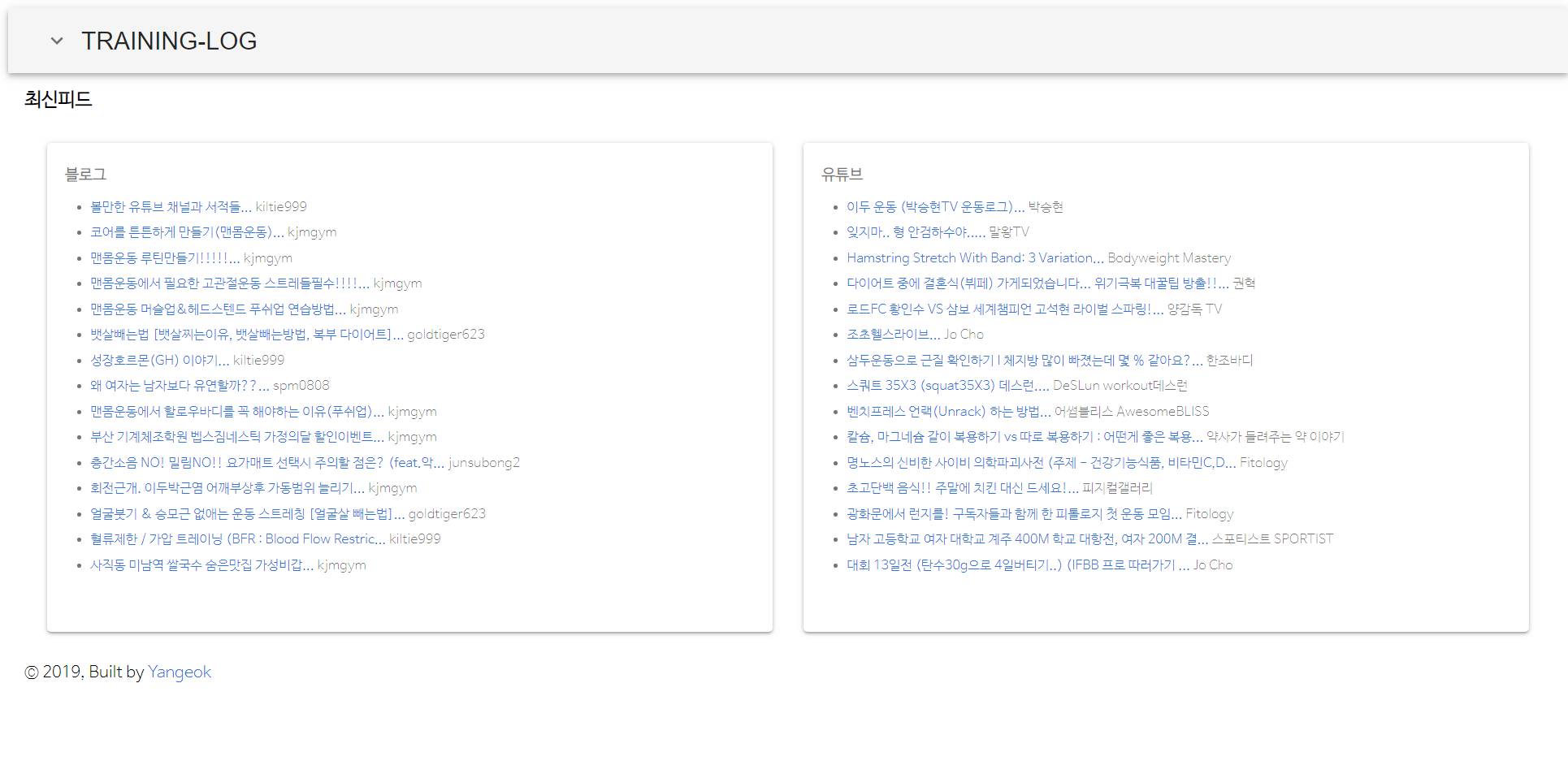
- 운동 관련 블로그, 유튜브를 수집해서 포스팅, 영상을 수집해 보기좋게 제공하고 있습니다. 데이터베이스가 날아가더라도 재수집을 통해 수 분 안에 복구됩니다. 아래 이미지는 서비스의 전체적인 구조입니다.
- 모바일 버전으로도 볼 수 있습니다.
- 깃허브 저장소는 아래와 같습니다.
- training-front: 프론트엔드 코드 저장소입니다.
- training-back: 백엔드 API서버 코드 저장소입니다.
- training-rss-feed: 백엔드 피드컬렉터 코드 저장소입니다.
- training-list: 유튜브, 블로그 목록을 yml파일로 수집하는 저장소입니다.
-
기술스택은 아래와 같습니다.
- 프로젝트 구조는 여기에서 확인할 수 있습니다.
- 데모페이지는 여기에서 확인할 수 있습니다.
{kind=link}
{kind=link}
Turing Backend API Server
- 프리랜서 에이전트 서비스인 turing.com에서 테스트 문제로 내주는 백엔드 웹서버입니다.
- 다음은 깃허브 저장소입니다.
- 기술스택은 아래와 같습니다.
Github Pages 개발블로그
- Jekyll 테마 Centrarium을 이용해서 만들었습니다. 시작한지는 얼마 안됐고 막힌부분을 풀어나가면서 잊어먹을 것같은 내용이나 한글로 포스팅이 올라오지 않은 내용을 주로 포스팅하고 있습니다. 또한 TIL에 정리한 내용 중 포스팅할만큼 내용이 정리가 된 경우에도 글을 쓰고 있습니다.
- 다음은 깃허브 저장소입니다.
- 설치 플러그인은 다음과 같습니다.
Shopping Mall
- 첫 팀프로젝트입니다. 천천히 같이 공부하며 진행한 프로젝트라 기능구현하는데 시간이 많이 지체되었고 현재 중단된 프로젝트입니다.
- 깃허브 저장소는 아래와 같습니다.
- mall-front: 프론트엔드 코드 저장소입니다.
- mall-back: 백엔드 코드 저장소입니다.
-
기술스택은 다음과 같습니다.
- 프로젝트 구조는 여기에서 확인할 수 있습니다.
- 데이터베이스 구조는 여기에서 확인할 수 있습니다.
- 데모페이지는 여기에서 확인할 수 있습니다.
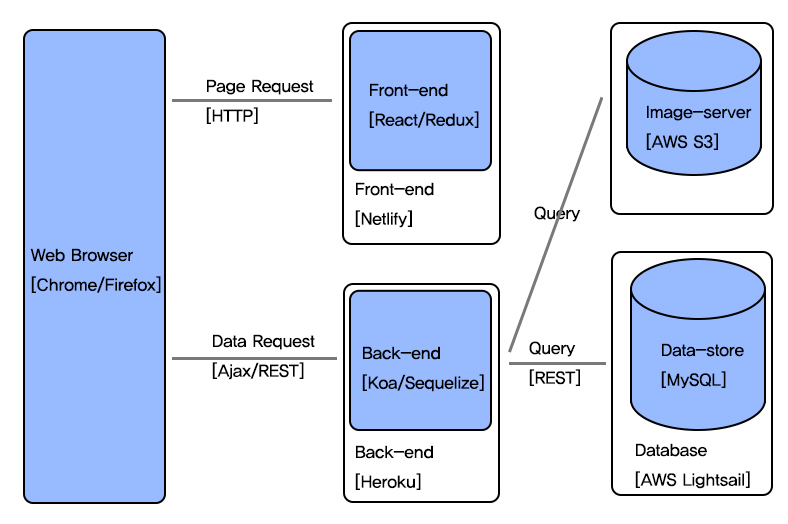{kind=link}
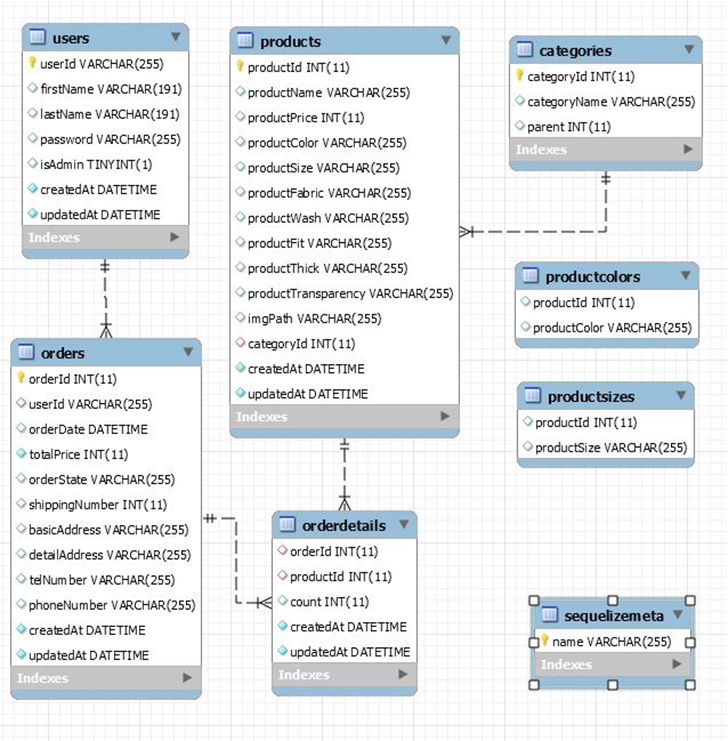{kind=link}
{kind=link}
GitHub Repository
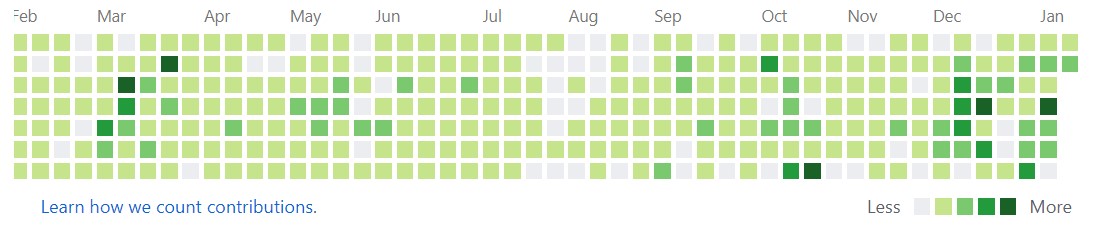
- 쓸데 있는 꾸준한 커밋으로 잔디밭을 만드는 것을 목표로 하고 있습니다.
- Github TIL을 아래에서 연월 별로 확인할 수 있습니다.