GA Reporting api v4 사용하기
by Yangeok
환경
- WSL1 (Ubuntu 18.04)
- Python 3.8
목적
google analytics에 Audience - User Explorer에 있는 정보들을 하나씩 다운받을 수는 있었지만, 여러개를 한 번에 받아올 수가 없었습니다.

api를 사용해서 가져오면 한 번에 긁어올 수 있을 것 같았습니다. 조금 찾아보니 Analytics Reporting API v4라는게 있더라구요. 이 api를 사용해서 대량의 사용자 활동정보를 긁어올 수가 있었습니다.
전략은 이렇습니다.
- 인증키와 view id를 받아 api에 요청을 보낼 수 있는 인증키 파일을 생성한다.
- ga에서 client id를 수집해온다.
- client id를 가지고 api에 요청을 보내 받은 응답을 파일로 저장한다.
자, 이제 차근차근 살펴볼까요?
API 미리보기
batchGet()과 search() 중 우리가 사용할 api는 userActivity().search()입니다. 여기를 클릭하면, 요청/응답 파라미터를 확인할 수 있습니다. api 문서 상에서 간단한 테스트를 해볼 수도 있습니다.
request body에 원하는 파라미터를 입력합니다.

인증을 거친 후 response body에 다음과 같이 json이 찍힙니다.
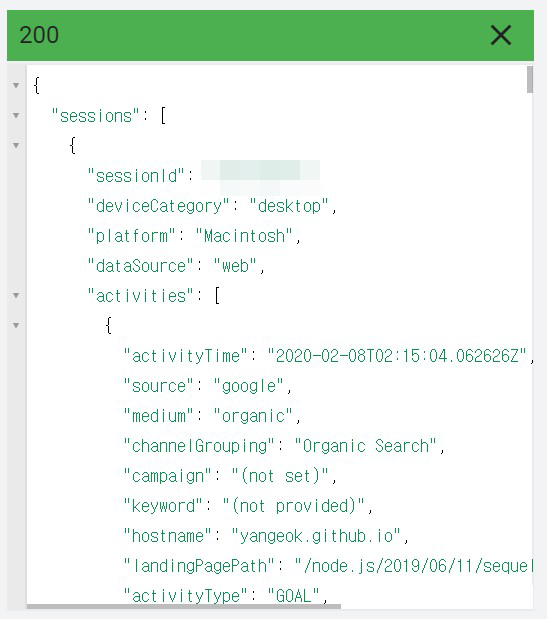
프로젝트 구조
아래처럼 폴더구조와 파일을 생성합니다.
$ mkdir src src/data src/csv src/json &&\
touch start.sh docker-compose.yml &&\
touch src/index.py src/start.sh src/install.sh src/requirements.txt
아래와 같은 디렉토리 구조가 나옵니다.
┣ 📂src
┃ ┣ 📂csv
┃ ┣ 📂data
┃ ┣ 📂json
┃ ┣ 📜index.py
┃ ┣ 📜install.sh
┃ ┣ 📜requirements.txt
┃ ┗ 📜start.sh
┣ 📜.gitignore
┣ 📜docker-compose.yml
┣ 📜README.md
┗ 📜start.sh
src/csv는 Audience - User Explorer에 있는 리스트를 파일로 모아둡니다. 아직 client id를 수집하는 api를 찾지 못했습니다. 혹시 어떤 api를 쓰면 1234512345.1234512345 형태의 client id를 전부 다 가져올 수 있는지 알고 계시는 분은 제보 부탁드립니다.
src/data는 client_secret.json, credentials.dat같은 인증 키파일을 저장합니다.
src/json은 api를 사용해 추출한 사용자 활동 정보들을 저장합니다.
도커라이징
docker 컨테이너 위에서 코드가 동작하도록 했습니다. 리눅스, 유닉스 환경을 사용중이신 분들은 이 과정을 건너뛰셔도 됩니다.
docker command를 사용하는 방법은 다음과 같습니다.
# start.sh
docker run -it \
-v $(pwd | sed 's/^\/mnt//')/src:/usr/src/app \
-w /usr/src/app \
python:latest bash
아래와 같이 컨테이너에 접속합니다.
sh start.sh
docker-compose를 사용하는 방법은 다음과 같습니다.
# docker-compose.yml
version: "3.7"
services:
ga:
image: python:latest
volumes:
- ./src:/usr/src/app
working_dir: /usr/src/app
아래와 같이 컨테이너에 접속합니다.
docker-compose run ga bash
라이브러리 세팅
install.sh에 다음과 같이 작성 후 저장합니다.
pip install -r requirements.txt &&\
pip install --upgrade google-api-python-client
requirements.txt에 다음과 같이 작성 후 저장합니다.
httplib2==0.17.0
pandas==0.25.3
oauth2client==4.1.3
apiclient==1.0.4
times==0.7
install.sh을 실행해 라이브러리를 설치합니다.
sh install.sh
참고로, requirements.txt에 있는 모듈 외에 클라이언트 라이브러리인 google-api-python-client가 최신버전이 아닌 상태라면 아래와 같이 모듈을 찾지 못하는 에러가 발생하더라구요.
ModuleNotFoundError: No module named ‘apiclient.discovery’
OAuth 인증
인증을 위한 api key 파일
구글 개발자 콘솔에서 Credentials로 들어가 + CREATE CREDENTIALS를 통해 인증정보를 새로 만듭니다.

어떤 애플리케이션에서 정보를 보여줄게 아니라, 파일로만 저장해서 쓰기 위한 스크립트만 작성할 것이기때문에, Other를 선택합니다.

client_secret_*.json 형태의 인증키 파일을 다운받아 src/data에 client_secret.json으로 저장합니다.
view id 가져오기
애널리틱스에 들어가거나 query explorer에서 view id를 가져올 수 있습니다.
-
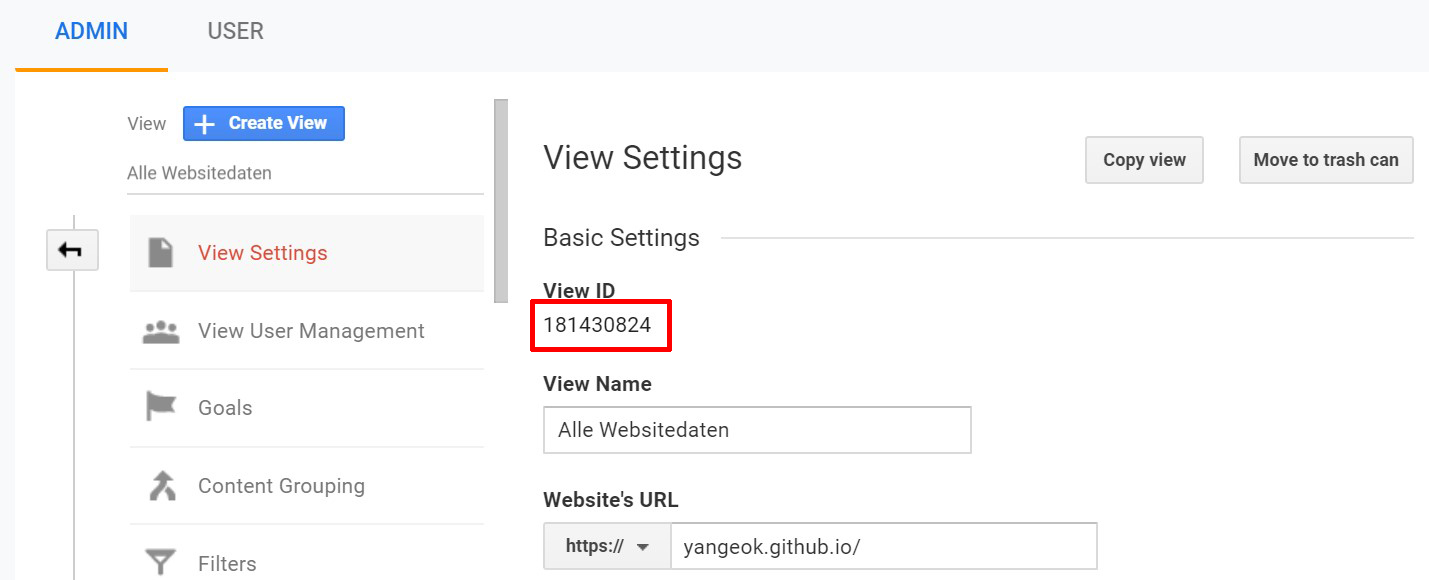
ga에서 가져오는 방법
- Admin - View Settings에서 확인할 수 있습니다.

-
query explorer에서 가져오는 방법
- Account Explorer에서 확인할 수 있습니다.

링크에 있는 샘플코드를 약간 고쳐다가 사용합니다.
아래는 모듈 로드 및 변수 선언입니다.
import os, glob, json, httplib2, time # 추가
import argparse
from apiclient.discovery import build
from oauth2client import client
from oauth2client import file
from oauth2client import tools
START_DATE = os.environ['START_DATE'] # 추가
END_DATE = os.environ['END_DATE'] #추가
TOKEN_FILE_NAME = './data/credentials.dat' # 추가
# CLIENT_SECRETS_PATH = 'client_secrets.json'
CLIENT_SECRET = './data/client_secret.json' # 변경
# SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
SCOPE = 'https://www.googleapis.com/auth/analytics.readonly' # 변경
VIEW_ID = 'VIEW_ID'
아래까지 작성하면 oauth 인증을 통해 credentials.dat를 생성해낼 수 있습니다.
def initialize_analyticsreporting():
parser = argparse.ArgumentParser(
formatter_class=argparse.RawDescriptionHelpFormatter,
parents=[tools.argparser]
)
flags = parser.parse_args()
flow = client.flow_from_clientsecrets(
CLIENT_SECRET,
scope=SCOPE,
message=tools.message_if_missing(CLIENT_SECRET)
)
# storage = file.Storage('analyticsreporting.dat')
storage = file.Storage(TOKEN_FILE_NAME) # 변경
credentials = storage.get()
if credentials is None or credentials.invalid:
credentials = tools.run_flow(flow, storage, flags)
http = credentials.authorize(http=httplib2.Http())
analytics = build('analyticsreporting', 'v4', http=http)
return analytics
def main():
analytics = initialize_analyticsreporting()
if __name__ == '__main__':
main()
이제 터미널에서 아래와 같은 명령어로 파일을 실행합니다.
python index.py --noauth_local_webserver
--noauth_local_webserver 플래그를 같이 작성하지 않으면 아래와 같은 경고메시지가 발생하고, 링크를 타고 들어가서 권한부여를 하더라도 리디렉션이 일어나지 않습니다.
If your browser is on a different machine then exit and re-run this application with the command-line parameter
위의 링크를 타고 들어가면 아래와 같이 권한을 허용하는 페이지가 나옵니다. 여기서 확인과 허용을 누릅니다.


아래와 같이 인증코드를 복사해서 애플리케이션에 붙여넣기 하라고 합니다.

터미널로 돌아가서 아래처럼 값을 붙여넣어주면, credentials.dat 파일이 생성됩니다.
Enter verification code: <VERIFICATION_CODE>
사용자 활동내역 수집
client id 수집
Audience - User Explorer에서 날짜지정을 한 후에 사용자 목록을 csv파일로 src/csv에 다운받습니다.
파일 내용은 다음과 같은 형태입니다.

우리가 사용할 부분은 고객 ID라고 된 client id를 사용할겁니다. 필요한 부분만 빼오기 위해 다음과 같은 함수를 작성합니다. 아래 함수는 src/csv에 있는 모든 파일들을 열어서 client id만 추출한 후에 리스트에 저장합니다.
def get_client_id():
file_names = glob.glob('./csv/*.csv')
arr = []
for file_name in file_names:
rows = list(open(file_name, 'r'))[7:]
for row in rows:
row = row.split(',')[0]
arr.append(row)
print(f'\n> client_id length: {len(arr)}\n')
return arr
main함수에 아래와 같이 구문을 추가합니다.
def main():
analytics = initialize_analyticsreporting()
client_ids = get_client_id()
for client_id in client_ids:
time.sleep(10)
response = get_report(analytics, client_id)
save_response(response, client_id)
api 요청보내기
csv에서 뽑아낸 client id를 가지고 reporting api에 요청을 보내고, 받은 응답을 저장하는 함수를 작성합니다.
def get_report(analytics, client_id):
print(client_id)
body = {
'dateRange': {
'startDate': START_DATE,
'endDate': END_DATE
},
'viewId': VIEW_ID,
'user': {
'type': 'CLIENT_ID',
'userId': client_id
},
'activityTypes': ['ECOMMERCE']
}
return analytics.userActivity().search(body=body).execute()
def save_response(response, client_id):
print(f'> saving client {client_id}\n')
with open(f'./json/{client_id}.json', 'w', encoding='utf-8') as make_file:
json.dump(response, make_file, indent="\t")
userActivity().search()은 reporting().batchGet()과는 요청 바디의 형태가 다릅니다. api 문서 예제에는 search() 메서드의 사용법이 따로 나와있지 않아 기술합니다. 아래는 batchGet()는 reportRequest 배열 안에 요청들을 넣음으로서, 복수의 viewId에 대한 요청을 보낼 수 있지만, search()는 한 번 요청에 하나의 viewId에 대한 요청밖에 보낼 수 없습니다. 좀 생각해보면 당연한건데, 예제에 search() 메서드의 사용법이 따로 나와있질 않아 삽질하고 나서야 글로 남깁니다. api 문서를 꼼꼼히 읽읍시다..
스크립트를 실행하면 src/json에 사용자 활동에 대한 json 파일이 쌓여있는 것을 확인할 수 있을겁니다.
제한 및 할당량
Limits and Quotas 페이지에서 api 요청 할당량을 확인할 수 있습니다. 우리에게 적용될 수 있는 부분을 추려봤습니다.
- 프로파일당 10,000건의 요청 가능
- 프로파일당 동시 10건의 요청 가능
- 프로젝트당 100초마다 2,000건의 요청 가능
- 프로젝트당 유저마다 1초에 1건의 요청 가능
- 프로젝트당 매일 50,000건의 요청 가능
1초에 1건의 요청을 보내다 보면 상태코드 403, 429를 반환하더라구요. 그래서 안전하게 timeout을 10초씩 줘서 유저 활동 정보를 추출했더니 안전하게 잘 되더랍니다.
TL;DR
현재 client library를 알파 내지 베타로 제공하고 있는 언어들도 많은 스타 수를 보면 많은 사람들의 관심을 얻고 있는 것으로 보입니다. 같은 코드를 nodejs 알파버전 라이브러리로도 한 번 포팅해보면 구글 api와 조금 더 가까워질 수 있을 것 같습니다.
오타 혹은 잘못된 부분이 있다면 댓글 달아주시면 감사하겠습니다 :)