TypeORM 데코레이터 씹어먹기
by Yangeok
TL;DR
TypeORM 공식문서의 순서에 따라 데코레이터들을 소개합니다. 공식문서와 100% 일치하지 않고 늘릴 부분은 늘리고, 줄일 부분은 줄였음을 확인하신 후에 읽어주세요. SQL, ORM과 OOP에 대한 기본 지식을 가지고 계시는 분이라면 읽기에 더 수월할 수 있습니다! (데코레이터 사용법이 JPA와 아주 유사합니다)
아래 예제 코드들은 TypeORM에 MySQL을 붙여서 사용한 예제입니다.
Entity
Entity
데이터베이스 테이블을 정의하기 전에 실행해야하는 데코레이터입니다. 테이블명을 따로 지정하지 않아도 클래스명으로 매핑하지만, 옵션으로 테이블명을 지정할 수 있습니다.
@Entity('users')
export class User {}
아래와 같이 옵션을 추가적으로 지정할 수 있습니다.
name: 테이블 이름. 지정하지 않으면 테이블 이름은 엔티티 클래스명으로 생성됨database: 선택된 DB서버의 데이터베이스 이름schema: 스키머 이름engine: 테이블 생성 중에 설정할 수 있는 DB엔진 이름synchronize:false로 설정할 시 스키머 싱크를 건너뜀orderBy:QueryBuilder과find를 실행할 때 엔티티의 기본순서를 지정함
@Entity({
name: 'users',
engine: 'MyISAM',
database: 'example_dev',
schema: 'schema_with_best_tables',
synchronize: false,
orderBy: {
name: 'ASC',
id: 'DESC'
}
})
export class User {}
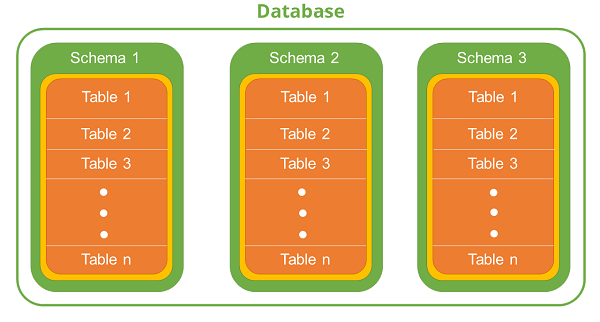
MySQL에서는 schema와 database가 따로 분리되어있지 않아요. 아래 이미지와 같이 OracleDB에서는 schema를 따로 분리해서 database에 할당된 사용자로 사용한다고 합니다.
Entity inheritance
id, title, description이란 공통된 칼럼을 가진 entity인 Photo, Question, Post를 아래와 같이 작성해볼까요?
@Entity()
export class Photo {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
description: string
@Column()
size: string
}
@Entity()
export class Question {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
description: string
@Column()
answersCount: number
}
@Entity()
export class Post {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
description: string
@Column()
viewCount: number
}
테이블 필드들을 중복 없이 DRY하게 바꾸는 3가지 패턴을 보여드릴거에요.
Concrete table inheritance
위에서 중복된 칼럼인 id, title, description을 아래와 같이 베이스가 되는 추상 클래스를 선언한 다음 확장할 수 있습니다.
참고로 active record 패턴을 사용할 예정이라면, BaseEntity라는 이름은 피하는게 좋습니다. typeorm에서 제공하는 클래스인 BaseEntity는 기본 쿼리 메서드 hasId, save, remove 등의 메서드를 담은 클래스입니다.
export abstract class Content {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
description: string
}
@Entity()
export class Photo extends Content {
@Column()
size: string
}
@Entity()
export class Question extends Content {
@Column()
answersCount: number
}
@Entity()
export class Post extends Content {
@Column()
viewCount: number
}
보통 테이블마다 id, createdAt, updatedAt 필드는 꼭 들어가잖아요? 필드 3개를 적는 노가다를 없애는데는 이 패턴이면 충분합니다. 아래 소개할 패턴들은 특정 의도를 가지고 튜닝할 때 사용하는 것이 유의미해 보입니다.
Single table inheritance
@TableInheritance(), @ChildEntity()를 사용하는 방법입니다. 이 방법은 데이터베이스에 Content 테이블이 생성됩니다. Content 위에 @Entity()를 선언해줘야 아래와 같은 패턴을 사용할 수 있습니다.
@Entity()
@TableInheritance({ column: { type: 'varchar', name: 'type' }})
export class Content {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
description: string
}
@ChildEntity()
export class Photo extends Content {
@Column()
size: string
}
@ChildEntity()
export class Question extends Content {
@Column()
answersCount: number
}
@ChildEntity()
export class Post extends Content {
@Column()
viewCount: number
}
Embedded entities
이름이 비슷하고 타입이 같은 칼럼들을 묶는 패턴입니다. User.name은 User.nameFirst, User.nameLast로 분기합니다. Name은 데코레이터 @Entity()가 붙어있지 않기때문에 위의 패턴처럼 실제 테이블이 생겨나지는 않습니다.
export class Name {
@Coulmn()
first: string
@Column()
last: string
}
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: string
@Column(type => Name)
name: Name
@Column()
isActive: boolean
}
DESC문을 돌리면 아래와 같이 나옵니다.
+-------------+--------------+----------------------------+
| user |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| nameFirst | varchar(255) | |
| nameLast | varchar(255) | |
| isActive | boolean | |
+-------------+--------------+----------------------------+
ViewEntity
여기서 잠깐, SQL view이란 뭘까요?
- view는 하나의 가상 테이블이다.
- 실제 데이터가 저장되는 것은 아니지만, view를 통해 데이터를 가상 테이블로 관리가 가능하다.
- 1개의 view로 여러 테이블의 데이터를 조회할 수 있다.
- 복잡한 쿼리를 통해 얻을 수 있는 결과를 간단한 쿼리로 얻을 수 있게 도와준다.
- 특정 기준에 따른 사용자 별로 다른 데이터를 액세스할 수 있도록 도와줄 수도 있다.
- 조회 대상을 줄이고 싶을 때 사용할 수 있다.
데코레이터에 들어가는 인자가 아래와 같이 @Entity()와는 약간 다릅니다.
name: 테이블 이름. 지정하지 않으면 테이블 이름은 엔티티 클래스명으로 생성됨database: 선택된 DB서버의 데이터베이스 이름schema: 스키머 이름expression: view를 정의. 꼭 있어야하는 파라미터로 SQL쿼리문이나queryBuilder체이닝 메서드가 들어갈 수 있음
expression은 SQL 쿼리문이나 QueryBuilder에 체이닝할 수 있는 메서드가 들어갈 수 있습니다. 특이점으로는 필드명 위에 들어가는 데코레이터를 id까지 전부 @ViewColumn()을 사용해야 한다는 점이 있습니다. 만약 사용을 고려한다면, JOIN을 쳐서 테이블끼리 연결을 시키냐, 아니면 view를 통해 나중에 자주 사용할 가상 테이블을 미리 만들어두냐의 차이로 생각할 수 있습니다.
아래와 같이 코드를 작성할 수 있습니다.
@ViewEntity({
expression: `
SELECT "post"."id" AS "id", "post"."name" AS "name", "category"."name" AS "categoryName"
FROM "post" "post"
LEFT JOIN "category" "category" ON "post"."categoryId" = "category"."id"
`
})
export class PostCategory {
@ViewColumn()
id: number
@ViewColumn()
name: string
@ViewColumn()
categoryName: string
}
구조가 복잡하고, 여러군데서 호출하는 데이터의 경우 미리 ViewEntity로 view 테이블을 만들어두면 좋을 것 같아요.
Column
Column
entity의 속성을 테이블 칼럼으로 표시합니다.
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ tpye: 'varchar', length: 200, unique: true })
firstName: string
@Column({ nullable: true })
lastName: string
@Column({ default: false })
isActive: boolean
}
@Column()에 들어갈 수 있는 옵션들 중 중요하다고 판단한 것들은 아래와 같습니다.
type: ColumnType: javascript의 원시타입들을 세분화해서 사용할 수 있습니다. 타입을 정의하는 방법은 다음과 같습니다.
// way 1
@Column('int')
// way 2
@Column({ type: 'int' })
다음은 MySQL 기준으로 아래와 같은 타입들을 @Column() 데코레이터의 인자로 사용할 수 있습니다.
length: string | number: javascript의 원시타입들을 세분화해서 사용하기 위해type옵션과 같이 사용할 수 있다.onUpdate: string: cascading을 하기 위한 옵션으로ON UPDATE트리거이다.nullable: boolean: 칼럼을NULL이나NOT NULL로 만드는 옵션이다. 기본값은false이다.default: string: 칼럼에DEFAULT값을 추가한다.unique: boolean: 유니크 칼럼이라고 표시할 수 있다. 유니크 constraint를 만든다. 기본값은false이다.enum: string[] | AnyEnum: 칼럼의 값으로enum을 사용할 수 있다.enum은 db단에서 처리할 수도, orm단에서 처리할 수도 있다.
@Column({ enum: AnyEnum })
data: AnyEnum
enumName: string: 다른 테이블에서 같은enum을 사용하는 경우 필요하다.transformer: { from(value: DatabaseType): EntityType, to(value: EntityType): DatabaseType }: 아래와 같은 코드를 만들어내서 json을 문자열로 만들고 파싱하는 역할을 한다. 또는 boolean을 integer로 바꿔주는 일도 할 수 있다.
import { ValueTransformer } from 'typeorm'
class SomeTransformer implements ValueTransformer {
to (value: Map<string, number>): string {
return JSON.stringify([...value])
}
from (value: string): Map<string, number> {
return new Map(JSON.parse(value))
}
}
IdColumn
PrimaryColumn
@Column()의 옵션인 primary를 대체할 수 있습니다. PK를 만드는 역할을 합니다.
PrimaryGeneratedColumn
자동생성되는 ID값을 표현하는 방식을 아래와 같이 2가지 옵션을 사용할 수 있도록 도와줍니다.
increment:AUTO_INCREMENT를 사용해서 1씩 증가하는ID를 부여한다. 기본 옵션이다.uuid: 유니크한uuid를 사용할 수 있다.
// using increment
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
}
// using uuid
@Entity()
export class User {
@PrimaryGeneratedColumn('uuid')
id: string
}
Generated
PK로 쓰는ID외에 추가로uuid를 기록하기 위해서 사용할 수 있습니다.
@Entity()
export class User {
@Column()
@Generated('uuid')
uuid: string
}
DateColumn
CreateDateColumn
해당 열이 추가된 시각을 자동으로 기록합니다. 옵션을 적지 않을시 datetime 타입으로 기록됩니다.
@Entity()
export class User {
@CreateDateColumn()
createdAt: Date
}
UpdateDateColumn
해당 열이 수정된 시각을 자동으로 기록합니다. 옵션을 적지 않을시 datetime 타입으로 기록됩니다.
@Entity()
export class User {
@UpdateDateColumn()
updatedAt: Date
}
DeleteDateColumn
여기서 잠깐, soft delete이란 뭘까요?
- 데이터 열을 실제로 삭제하지 않고, 삭제여부를 나타내는 칼럼인
deletedAt을 사용하는 방식이다. - 일반적인 삭제 대신 삭제된 열을 갱신하는
UPDATE문을 사용하는 방식이다. - 시각이 기록되지 않은 열들만 필터해서 쿼리하도록 도와주는 역할을 한다.
- 다른 테이블과
JOIN시 항상 삭제된 열을 검사해서 성능이 떨어진다. - 복구하거나 예전 기록을 확인하고자 할 때 간편하다.
해당 열이 삭제된 시각을 자동으로 기록합니다. deletedAt에 시각이 기록되지 않은 열들만 쿼리하기 위해 TypeORM의 soft delete 기능을 활용할 수 있습니다. 옵션을 적지 않을시 datetime 타입으로 기록됩니다.
@Entity()
export class User {
@DeleteDateColumn()
deletedAt: Date
}
Relation
테이블간의 관계는 1:1, 1:N, M:N 관계가 있습니다. 그 중 1:N 관계는 실생활에서 널리 찾을 수 있어서 제외합니다. 나머지 관계들의 예시는 아래와 같이 들 수 있습니다.
- 1:1은 회원정보와 회원 프로필정보, 사원번호와 사원 주민번호, 학생과 학생 연락처정보
- M:N은 사원과 업무, 영화와 영화배우, 학생과 수업
OneToOne
User와 Profile 테이블을 아래와 같이 준비합니다. 둘의 관계는 1:1 관계입니다. User에서 target relation type을 Profile로, Profile에서 target relation type은 User로 지정했습니다. 다시 언급할 @JoinColumn()을 사용한 필드는 FK로 타겟 테이블에 등록됩니다. @JoinColumn()은 반드시 한쪽 테이블에서만 사용해야 합니다.
관계는 단방향과 양방향 모두 작성이 가능합니다. uni-directional은 @OneToOne()을 한쪽에만 써주는 것을 bi-directional은 양쪽에 모두 써주는 것을 의미합니다. 아래는 bi-directional 관계입니다.
@Entity()
export class Profile {
@PrimaryGeneratedColumn()
id: number
@Column()
gender: string
@Column()
photo: string
@OneToOne(() => User, user => user.profile)
user: User
}
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
@OneToOne(type => Profile, profile => profile.user)
@JoinColumn()
profile: Profile
}
DESC문을 돌리면 아래와 같이 나옵니다.
+-------------+--------------+----------------------------+
| profile |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| gender | varchar(255) | |
| photo | varchar(255) | |
| userId | int(11) | FOREIGN KEY |
+-------------+--------------+----------------------------+
+-------------+--------------+----------------------------+
| user |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| name | varchar(255) | |
| profileId | int(11) | FOREIGN KEY |
+-------------+--------------+----------------------------+
이것으로 끝난 것은 아닙니다. user.profile나 profile.user를 검색하기 위해서는 관계를 지정해주는 작업이 필요합니다. 아래와 같이 2가지 패턴으로 관계를 지정해 호출하는 것이 가능합니다.
// using find* method
const userRepo = connection.getRepository(User)
const users = await userRepo.find({ relations: ['profile'] })
// using query builder
const users = await connection
.getRepository(User)
.createQueryBuilder('user')
.leftJoinAndSelect('user.profile', 'profile')
.getMany()
ManyToOne/OneToMany
User와 Photo 테이블을 아래와 같이 준비합니다. 둘의 관계는 1:M 관계입니다. 사용자는 여러장의 사진을 가질 수 있습니다.
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
@OneToMany(type => Photo, photo => photo.user)
photos: Photo[]
}
@Entity()
export class Photo {
@PrimaryGeneratedColumn()
id: number
@Column()
url: string
@ManyToOne(type => User, user => user.photos)
user: User
}
@OneToMany()/@ManyToOne()에서는 @JoinColumn()을 생략할 수 있습니다. @OneToMany()는 @ManyToOne()이 없으면 안됩니다. 하지만 반대로 @ManyToOne()은 @OneToMany()이 없어도 정의할 수 있습니다. @ManyToOne()을 설정한 테이블에는 relation id가 외래키를 가지고 있게 됩니다.
DESC문을 돌리면 아래와 같이 나옵니다.
+-------------+--------------+----------------------------+
| photo |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| url | varchar(255) | |
| userId | int(11) | FOREIGN KEY |
+-------------+--------------+----------------------------+
+-------------+--------------+----------------------------+
| user |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| name | varchar(255) | |
+-------------+--------------+----------------------------+
마찬가지로 user.photos나 photo.user를 검색하기 위해서는 관계를 지정해주는 작업이 필요합니다. 두 객체중 어느 한 곳에서 관계를 명시해줘야 합니다. 아래와 같이 2가지 패턴으로 관계를 지정해 호출하는 것이 가능합니다.
// using find* method
const userRepository = connection.getRepository(User);
const users = await userRepository.find({ relations: ['photos'] })
// or from inverse side
const photoRepository = connection.getRepository(Photo);
const photos = await photoRepository.find({ relations: ['user'] })
// using query builder
const users = await connection
.getRepository(User)
.createQueryBuilder('user')
.leftJoinAndSelect('user.photos', 'photo')
.getMany()
// or from inverse side
const photos = await connection
.getRepository(Photo)
.createQueryBuilder('photo')
.leftJoinAndSelect('photo.user', 'user')
.getMany()
ManyToMany
Category와 Question 테이블을 아래와 같이 준비합니다. 둘의 관계는 N:M 관계입니다. 카테고리는 여러개의 질문을 가질 수 있고, 질문 또한 여러개의 카테고리를 가질 수 있습니다. 관계는 단방향과 양방향 모두 작성이 가능합니다.
@Entity()
export class Category {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
}
@Entity()
export class Question {
@PrimaryGeneratedColumn()
id: number
@Column()
title: string
@Column()
text: string
@ManyToMany(() => Category)
@JoinTable()
categories: Category[]
}
@ManyToMany() 관계에서는 @JoinTable()이 반드시 필요합니다. 한쪽 테이블에만 @JoinTable()을 넣어주면 됩니다.
DESC문을 돌리면 아래와 같이 나옵니다.
+-------------+--------------+----------------------------+
| category |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| name | varchar(255) | |
+-------------+--------------+----------------------------+
+-------------+--------------+----------------------------+
| question |
+-------------+--------------+----------------------------+
| id | int(11) | PRIMARY KEY AUTO_INCREMENT |
| title | varchar(255) | |
| text | varchar(255) | |
+-------------+--------------+----------------------------+
+-------------+--------------+----------------------------+
| question_categories_category |
+-------------+--------------+----------------------------+
| questionId | int(11) | PRIMARY KEY FOREIGN KEY |
| categoryId | int(11) | PRIMARY KEY FOREIGN KEY |
+-------------+--------------+----------------------------+
단 @ManyToMany()에서 옵션 cascade가 true인 경우 soft delete를 할 수 있습니다. 필요에 따라 사용할 수 있습니다.
마찬가지로 question.categories나 categories.questions를 검색하기 위해서는 관계를 지정해주는 작업이 필요합니다. 아래와 같이 2가지 패턴으로 관계를 지정해 호출하는 것이 가능합니다.
// using find* method
const questionRepository = connection.getRepository(Question)
const questions = await questionRepository.find({ relations: ['categories'] })
// using query builder
const questions = await connection
.getRepository(Question)
.createQueryBuilder('question')
.leftJoinAndSelect('question.categories', 'category')
.getMany()
Tree entity
여기서 잠깐, 셀프조인이란 뭘까요?
- 1개의 테이블에서 부모-자식 관계를 나타낼 수 있는 패턴
- 상품 카테고리(소,중,대분류)
- 사원(사원,관리자,상위관리자)
- 지역(읍/면/동,구/군,시/도)
TypeORM은 셀프조인을 아래와 같은 4가지 패턴으로 지원합니다.
Adjacency list
자기참조를 @ManyToOne(), @OneToMany() 데코레이터로 표현할 수 있습니다. 이 방식은 간단한 것이 가장 큰 장점이지만, JOIN하는데 제약이 있어 큰 트리를 로드하는데 문제가 있다고 합니다. 하지만 4중첩 쿼리까지는 성능상 문제를 경험하지 못했습니다.
@Entity()
export class Category {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
@Column()
description: string
@ManyToOne(type => Category, category => category.children)
parent: Category
@OneToMany(type => Category, category => category.parent)
children: Category[]
}
Nested set
@Tree(), @TreeChildren(), @TreeParent()를 사용한 또 다른 패턴입니다. 읽기 작업에는 효과적이지만 쓰기 작업에는 그렇지 않습니다. 여러 개의 루트를 가질 수 없다는 점도 문제이다. @Tree()의 인자로 nested-set이 들어갑니다.
@Entity()
@Tree('nested-set')
export class Category {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
@TreeChildren()
children: Category[]
@TreeParent()
parent: Category
}
Materialized path
구체화된 경로 혹은 경로 열거라고 부릅니다. 간단하고 효율적입니다. nested set과 사용방법은 같습니다. @Tree()의 인자로 materialized-path이 들어갑니다.
Closure table
부모와 자식 사이의 관계를 분리된 테이블에 특별한 방법으로 저장합니다. 읽기와 쓰기 모두 효율적으로 할 수 있습니다. nested set과 사용방법은 같습니다. @Tree()의 인자로 closure-table이 들어갑니다.
JoinColumn/JoinTable
아래는 아래 2개의 데코레이터에 공통으로 사용할 수 있는 옵션입니다.
eager옵션이 있어서 N+1 문제를 제어할 수 있음cascade,onDelete옵션이 있어 관계가 연결된 객체를 추가/수정/삭제되도록 할 수 있음. 버그를 유발할 수 있으니 주의해서 사용하는 것이 좋음
JoinColumn
@JoinColumn()을 사용하면 테이블에 자동으로 칼럼명과 참조 칼럼명을 합친 이름의 칼럼을 만들어냅니다.
외래키를 가진 칼럼명과 참조칼럼명을 설정할 수 있는 옵션을 가지고 있습니다. 설정하지 않으면 테이블명을 가지고 자동으로 매핑합니다. 아래와 같은 경우에는 categoryId라고 매핑되야 할 것을 category_id로 이름을 직접 지정할 수 있습니다. 주의할 점으로는 @ManyToOne()에서는 꼭 적지 않아도 categoryId를 칼럼을 자동으로 만들어주지만, @OneToOne()에서는 반드시 적어줘야 합니다.
@Entity()
export class Post {
@ManyToOne(type => Category)
@JoinColumn({
name: 'category_id',
referencedColumnName: 'name'
})
category: Category
}
@Entity()
export class Category {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
}
JoinTable
M:N 관계에서 사용하며 연결 테이블을 설정할 수 있습니다. @JoinTable()의 옵션을 사용해 연결 테이블의 칼럼명과 참조 칼럼명을 설정할 수 있습니다.
@Entity()
export class Question {
@ManyToMany(type => Category)
@JoinTable({
name: 'question_categories',
joinColumn: {
name: 'question',
referencedColumnName: 'id'
},
inverseJoinColumn: {
name: 'category',
referencedColumnName: 'id'
}
})
categories: Category[]
}
@Entity()
export class Category {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
}
RelationId
1:N/M:N 관계에서 entity에 명시적으로 관계가 있는 테이블의 칼럼 id를 적고싶은 경우, @RelationId()를 사용하면 됩니다. @RelationId()가 꼭 필요하지는 않지만 entity를 보면서 칼럼을 한 눈에 볼 수 있다는 장점이 있습니다. @RelationId()로 테이블을 조회하면 새로운 칼럼명 categoryId도 결과에 같이 들고올 수 있습니다.
// using many to one
@Entity()
export class Post {
@ManyToOne(type => Category)
category: Category
@RelationId((post: Post) => post.category)
categoryId: number
}
// using many to many
@Entity()
export class Post {
@ManyToMany(type => Category)
categories: Category[]
@RelationId((post: Post) => post.categories)
categoryIds: number[]
}
Subscriber
데이터베이스에 특화된 리스너로 CRUD 이벤트 발생을 리슨합니다. 다음과 같은 데코레이터들을 가지고 있습니다. @AfterLoad, @AfterInsert, @BeforeInsert, @AfterUpdate, @BeforeUpdate, @AfterRemove, @BeforeRemove로 데코레이터 이름을 보면 바로 이해가 가실거에요.
logging 옵션이 있긴 하지만 쿼리만을 보여주기때문에 한 줄씩 분석하기 위해 로그를 남기는 경우에는 지양하는 것이 좋습니다. 아래처럼 한 줄짜리 로그를 만들 수 있습니다.
import { Logger } from '@nestjs/common'
Logger.log(`Price changed from
${ event.databaseEntity.price } to
${ event.entity.price }`, 'Product Price Updated')
서버에 요청을 보내면 다음과 같이 로그가 찍히는 것을 확인할 수 있습니다.
 출처: Subscribers a.k.a Entity Listeners of TypeORM on NestJS
출처: Subscribers a.k.a Entity Listeners of TypeORM on NestJS
Others
Index/Unique/Check
Index
여기서 잠깐, soft delete이란 뭘까요?
- 테이블 쿼리 속도를 올려주는 자료구조를 말한다.
- 테이블 내 1개 혹은 그 이상의 칼럼을 이용해 생성할 수 있다.
- 인덱스는 보통 키-필드만 갖고있고, 테이블의 다른 세부항목을 갖지 않기때문에 보통 테이블을 저장하는 공간보다 더 적은 공간을 차지한다.
- 특정 칼럼 값을 가지고 있는 열이나 값을 빠르게 찾기 위해 사용한다.
- 인덱싱하지 않은 경우는 첫번째 열부터 전체 테이블을 걸쳐 연관된 열을 검색하기때문에 테이블이 클수록 쿼리비용이 커진다.
- 인덱싱을 한 경우는 모든 데이터를 조회하지 않고 데이터 파일의 중간에서 검색위치를 빠르게 잡을 수 있다.
WHERE절과 일치하는 열을 빨리 찾기 위해서 사용한다.JOIN을 실행할 때 다른 테이블에서 열을 추출하기 위해서 사용한다.- 데이터 양이 많고 변경보다 검색이 빈번한 경우 인덱싱을 하면 좋다.
 쉽게 말해 이런 책에서 transaction이란 주제가 어딨는지 목차 없이 찾으려면 눈물날지도 모릅니다. 책의 주요내용을 가나다순으로 정리한 목록이 있으면 찾기 쉬울텐데 인덱스가 바로 그 역할을 합니다.
쉽게 말해 이런 책에서 transaction이란 주제가 어딨는지 목차 없이 찾으려면 눈물날지도 모릅니다. 책의 주요내용을 가나다순으로 정리한 목록이 있으면 찾기 쉬울텐데 인덱스가 바로 그 역할을 합니다.
특정 칼럼에 인덱스를 걸 수 있습니다. 옵션으로 고유키를 부여할 수도 있습니다. 단일 칼럼에 인덱스를 걸고 싶으면 칼럼마다 추가할 수도 있지만, 테이블 전체에 인덱스를 걸고싶은 경우 @Entity()아래 @Index()를 추가할 수도 있습니다.
// using with single column
@Entity()
export class User {
@Index()
@Column()
firstName: string
@Index({ unique: true })
@Column()
lastName: string
}
// using with entity
@Entity()
@Index(['firstName', 'lastName'], { unique: true })
export class User {
@Column()
firstName: string
@Column()
lastName: string
}
Unique
특정 칼럼에 고유키 제약조건을 생성할 수 있습니다. @Unique()는 테이블 자체에만 적용하는 것이 가능합니다.
@Entity()
@Unique(['firstName', 'lastName'])
export class User {
@Column()
firstName: string
@Column()
lastName: string
}
Check
테이블에서 데이터 추가 쿼리가 날아오면 값을 체크하는 역할을 합니다.
@Entity()
@Check('"age" > 18')
export class User {
@Column()
firstName: string
@Column()
firstName: string
@Column()
age: number
}
Transaction
여기서 잠깐, 트랜잭션이란 뭘까요?
- 데이터베이스 내에서 하나의 그룹으로 처리해야하는 명령문을 모아서 처리하는 작업의 단위를 말한다.
- 여러 단계의 처리를 하나의 처리처럼 다루는 기능이다.
- 여러 개의 명령어의 집합이 정상적으로 처리되면 정상종료된다.
- 하나의 명령어라도 잘못되면 전체 취소된다.
- 트랜잭션을 쓰는 이유는 데이터의 일관성을 유지하면서 안정적으로 데이터를 복구하기 위함이다.
- 격리성 수준 설정을 통해 트랜잭션이 열려있는 동안 외부에서 해당 데이터에 접근하지 못하도록 락을 걸 수도 있다.
격리성 수준은 다음과 같이 분류할 수 있습니다. 아래로 갈수록 격리성 수준이 높아집니다.
READ UNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLE
global connection을 열어서 트랜젝션을 사용하는 경우는 아래와 같이 사용합니다.
await getManager().transaction('SERIALIZABLE', transactionalEntityManager => {})
하지만 global connection은 사이드이펙트가 많은 방법이기때문에 데코레이터나 queryRunner를 사용한 방법을 추천합니다. 아래는 데코레이터 @Transaction(), @TransactionManager(),
@TransactionRepository()를 사용한 패턴입니다.
// using transaction manager
@Transaction({ isolation: 'SERIALIZABLE' })
save(@TransactionManager() manager: EntityManager, user: User) {
return manager.save(user)
}
// using transaction repository
@Transaction({ isolation: 'SERIALIZABLE' })
save(user: User, @TransactionRepository(User) userRepository: Repository<User>) {
return userRepository.save(user)
}
아래는 queryRunner를 사용한 방법입니다. 다만 이 방법에서는 격리성 수준 설정이 불가능합니다.
startTransaction은 트랜잭션을 시작하는 메서드commitTransaction는 모든 변경사항을 커밋하는 메서드rollbackTransaction는 모든 변경사항을 되돌리는 메서드
await queryRunner.startTransaction()
try {
await queryRunner.manager.save(user)
await queryRunner.manager.save(photos)
await queryRunner.commitTransaction()
} catch (err) {
await queryRunner.rollbackTransaction()
} finally {
await queryRunner.release()
}
같은 주제의 슬라이드 쉐어 링크 첨부합니다. 본문에 오류가 있거나 보충해주시고 싶은 내용이 있다면 댓글 부탁드립니다!