Puppeteer로 크롤러 만들기 - 준비
by Yangeok
시리즈
체크리스트
커뮤니티, 포털, SNS는 게시판의 형태가 상이하기때문에 어떤 식으로 크롤할지 전략을 수립하는게 크롤러개발 시간을 단축하는데 큰 도움을 준다고 봅니다. 그래서 아래와 같이 체크리스트를 작성해봤습니다.
 출처: 나의 자존감 체크리스트
출처: 나의 자존감 체크리스트
통합검색이 구글검색인지 아닌지 확인한다
해당 게시판이 구글검색이라면 제 생각에 그 게시판은 포기하는게 낫다라고 봅니다. 구글검색으로 얻어온 결과가 페이지당 10개씩 10페이지까지밖에 나오지 않거든요. 즉 상단에 검색결과가 1000개라고 나와도 우리가 받아볼 수 있는 결과는 100개가 최대한입니다.
그래서 해당 커뮤니티에 검색기능이 구글검색으로 붙어있다면 사이트를 샅샅이 뒤져 자체 검색기능이 있나 찾아봅니다. 그래도 없다면 과감히 포기합니다.
UI가 페이지네이션인지 무한스크롤인지 확인한다
대부분 커뮤니티라면 페이지네이션 방식을 사용할 것이고, 대부분 sns라면 무한스크롤 방식을 사용할겁니다. 코드를 처음 짤때부터 접근하는 방식이 달라집니다.
페이지네이션인 경우, 페이지당 게시물 수가 정해져있기 때문에 해당 페이지에 있는 게시물 리스트를 뽑아와 크롤합니다. 계속해서 스크롤을 내리면 내릴 수록 html요소는 많아지기 때문에 크롤 속도 면에서 보면 무한스크롤 방식보다 훨씬 성능이 뛰어납니다.
무한스크롤인 경우, 화면 안에 들어있는 게시물 수만큼 루프를 돈 다음 루프를 돌지 않은 게시물이 0개일때, 더보기 버튼을 누르거나 스크롤을 하면서 크롤합니다.
 출처: Pagination vs Infinite Scrolling
출처: Pagination vs Infinite Scrolling
총 게시물 수 혹은 총 페이지 수가 명시되었는지 확인한다
둘 다 나와있다면 크롤하는 입장에서는 완전 땡큐지만, 그렇지 않을 가능성이 훨씬 큽니다.
총 게시물 수 혹은 총 페이지 수가 있는경우, 페이지당 게시물 수로 총 페이지 수를 계산할 수 있습니다.
- 총 게시물 수만 있는 경우:
<총 게시물 수>/<페이지당 게시물 수> = <총 페이지 수> - 총 페이지 수만 있는 경우: 총 페이지 수만 있음 됩니다ㅎㅎ
둘 다 나와있지 않은 경우는 마지막 페이지까지 클릭해서 마지막 페이지의 .text()값을 가져와서 사용해야 합니다.
Iframe이 적용되었는지 확인한다
$로 셀렉터를 찍어봐도 html요소가 반환되지 않는다면 Iframe이 적용됐는지를 의심해볼 수 있습니다. 하지만 걱정하지 않아도 됩니다. puppeteer에서는 프레임 이름만 안다면 Iframe을 뚫고 들어갈 수 있습니다. 다음과 같은 식으로 할 수 있습니다.
const frame = page.frames().find(frame => frame.name() === 'frameName');
프레임 이름을 정확히 모르는 경우에는 아래와 같이 찾는 방법도 있습니다.
const page = await browser.newPage();
for (const frame of page.mainFrame().childFrames()) {
if (frame.url().includes('partialFrameName')) {
console.log(`frameName: ${frame}`);
}
}
날짜필터링 기능이 queryString에 들어있나 확인한다
날짜 필터링을 하려면 조건문을 여러개 작성해야하는 불편함이 따를 수 있습니다. 네이버나 구글같이 필터링이 가능하다면 개발하는 입장에서는 세상 편합니다.
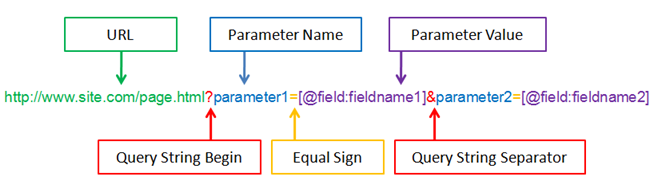 출처: Parameters as Query String Values
출처: Parameters as Query String Values
jQuery가 적용되었는지 확인한다
puppeteer 내장 함수 혹은 cheerio로 html 요소를 가져올때 참고하면 좋은 부분이기 때문입니다. jQuery에서 사용하는 $()를 두 라이브러리에서 사용 가능하기 때문입니다. 크롤하고자 하는 웹페이지에서 검사창을 띄워놓고 $를 쳐보면 어떠한 함수가 나올겁니다. 그러면 이 페이지에는 jQuery가 설치되어 있다는 소리죠. 하지만 네이버같은 경우에는 자체 라이브러리인 jindo가 설치되어 $가 먹히지 않고 $$를 써야하더라구요.
하지만 브라우저에서 $()로 요소를 반환하지 않고 $$()로만 반환한다고 한들 걱정할 것 없습니다.
Chrome Develeopers Tools documentation에서 아래와 같이 $마크가 용도 별로 있음을 알려줍니다.
Selecting Elements
There are a few shortcuts for selecting elements. These save you valuable time when compared to typing out their standard counterparts.
$() Returns the first element that matches the specified CSS selector. It is a shortcut for document.querySelector().
$$() Returns an array of all the elements that match the specified CSS selector. This is an alias for document.querySelectorAll()
만, 작동은 똑같이 하는 것 같습니다. 더 헷갈리기만 하더라구요. 브라우저에서 $()를 먼저 사용해보고 안된다면 $$()를 사용하는 편입니다. 같은 셀렉터를 읽어옴에도 $()와 $$()는 뒤에 붙는 메서드 혹은 객체 이름이 다름을 참고해주세요. 아래는 어떤 요소 안에 들어있는 텍스트만 가져오기 위한 코드입니다.
$('selector').text();
// something
$$('selector')[0].innerText;
// something
아래처럼 puppeteer 내장 함수를 사용한다면 아래와 같은 여러가지 메서드가 있습니다.
const item = await page.$('selector');
page.$()는 document.querySelector()를 페이지에서 실행합니다. 일치하는 셀렉터가 없다면 null을 반환합니다.
page.mainFrame().$(selector)와 같습니다.
const item = await page.$eval('selector', el => el);
page.$()는 document.querySelector()를 페이지에서 실행하고 콜백함수의 1번째 인자로 들어갑니다. 일치하는 셀렉터가 없다면 에러를 반환합니다.
page.mainFrame().$eval(selector, pageFunction)와 같습니다.
const items = await page.$$('selector');
page.$$()는 document.querySelectorAll()를 페이지에서 실행합니다. 일치하는 셀렉터가 없다면 빈 배열 []을 반환합니다.
page.mainFrame().$$(selector)와 같습니다.
const items = await page.$$eval('selector', el => el);
page.$$eval()는 Array.from(document.querySelectorAll(selector))를 페이지에서 실행합니다. 일치하는 셀렉터가 없다면 빈 배열 []을 반환합니다.
const fn = await page.evaluate('pageFunction');
const item = await page.evaluate(() => {
const $ = window.$;
return $('selector');
});
스크롤바 이동같은 함수를 바로 사용하거나 콜백으로 html요소를 반환합니다.
page.evaluate()에서 하는 행동을 콘솔에 찍어보면 브라우저 콘솔에서 확인할 수 있습니다. 그래서 window객체에 내장된 jQuery를 이용할 수 있죠. 대신 브라우저 하는 행동이라 아래와 같이 서버에 설치된 라이브러리를 사용할 수는 없습니다. 예컨대 .csv파일로 크롤한 내용을 써야하는 경우에는 객체에 들어있는 내용에 컴마가 들어간다면 안되겠죠. 이런 경우에는 .evaluate() 안에서 작업이 불가능합니다. 그래서 아래와 같이 밑에서 다시 선언해줘야하는 불편함이 따를 수 있습니다.
const item = await page.evaluate(() => {
const $ = window.$;
return {
date: $('dateSelector'),
title: $('titleSelector'),
user: $('userSelector'),
content: $('contentSelector'),
click: $('clickSelector'),
link: $('linkSelector')
};
});
const date = filter(item.date);
const title = filter(item.title);
const user = filter(item.user);
const content = filter(item.content);
const click = filter(item.click);
const link = filter(item.link);
이런 불편함이 없고자 cheerio를 사용할 수 있습니다.
const content = await page.content();
const $ = await cheerio.load(content);
const item = {
date: filter($('dateSelector')),
title: filter($('titleSelector')),
user: filter($('userSelector')),
content: filter($('contentSelector')),
click: filter($('clickSelector')),
link: filter($('linkSelector'))
};
코드가 훨씬 짧아짐을 알 수 있습니다. 하지만 cheerio는 한 페이지에 있는 html요소만 가져오기때문에 다른 페이지로 넘어가면 $를 다시 선언해줘야 하는 불편함이 따를 수 있습니다. 목적에 맞는 선택을 하는게 아주 중요합니다.
전략 수립
위에서 언급한 것처럼 게시판이 페이지네이션이냐 무한스크롤이냐에 따라 전략이 달라질겁니다. 우선 시작날짜, 끝날짜를 startDate, endDate 변수에 담아주고 나서 페이지네이션과 무한스크롤인 경우를 살펴보겠습니다. 참고로 날짜를 그냥 문자열로 비교하는 행동은 추천하지 않는 행동입니다. 혹시라도 모를 에러를 방지하고자 timestamp나 datetime형태로 비교하시길 추천드리는 바입니다.
페이지네이션
총 페이지 수를 알고 있다는 가정 하에 for 루프를 돌릴겁니다. 루프 안에서 첫페이지에서 게시물 리스트를 뽑아옵니다. 리스트의 1번째 게시물을 긁어와서 날짜를 검증합니다. startDate가 1번째 게시물보다 이후 면 크롤을 멈춥니다.
계속 루프를 돌면서 endDate가 게시물 리스트 요소의 날짜보다 이후 면 파일에 긁어온 데이터를 저장합니다.
계속 루프를 돌면서 startDate가 게시물 리스트 요소의 날짜보다 이후 가 아니면 파일에 긁어온 데이터를 저장합니다.
루프가 끝나거나 에러가 나면 페이지를 닫고 프로그램을 종료합니다.
무한스크롤
인기게시물같이 크롤할 요소가 아닌데 크롤할 게시물 요소와 중복된 클래스명을 가진 요소를 찾습니다. 싹 다 지워버립니다.
무한스크롤이라 정해진 페이지 수가 없기 때문에 while 루프를 돌릴겁니다. 예컨대 한 스크롤에 20개의 게시물이 있다고 가정하겠습니다. 타겟이 되는 게시물 중 1번째 게시물을 긁고 그 다음 게시물을 긁으려면 pseudo-classes인 :not(.className)을 사용해야 합니다.
1번째 게시물을 읽음과 동시에 이 게시물을 읽었음을 표시하기 위해 해당 요소에 어떤 클래스명을 추가합니다.
endDate가 해당 게시물 날짜와 같거나 이후 면 파일에 긁어온 데이터를 저장합니다.
반복해서 루프를 돌다 :not(.className)인 게시물이 없으면 한 스크롤을 내리는 행동을 반복하고 더 이상 요소가 없어 에러가 나면 페이지를 닫고 프로그램을 종료합니다.
브라우저 옵션 설정
headless, 디바이스, 뷰포트 설정, 자바스크립트, 폰트, 이미지, 스타일 로딩 등을 제어할 수 있습니다.
참고로 headless는 cli로 브라우징을 할 수 있는 것을 의미합니다. 코딩 시에는 브라우저가 어떤 식으로 작동하는지 모니터링하면서 하다가 크롤을 할 때에는 성능 향상을 위해서 headless 옵션을 true로 바꿉니다. headless 옵션은 다음과 같이 작성합니다.
const browser = await puppeteer.launch({ headless: true });
여기에서 디바이스 종류를 선택할 수 있습니다. 디바이스를 선택하면 해당 크기에 맞는 뷰를 브라우저가 제공합니다. 디바이스 옵션은 다음과 같이 작성합니다.
const device = puppeteer.devices['deviceName'];
await page.emulate(device);
대신 브라우저 창 크기는 제어해주지 않아 이런 일이 생기기도 합니다. 그래서 뷰포트를 제어해주는 옵션은 다음과 같이 두 가지 방법으로 작성합니다.
const width = 400,
height = 900;
// 이 방법
const browser = await puppeteer.launch({
args: [`--window-size${width},${height}`]
});
// 혹은
await page.setViewport({ width, height });
자바스크립트, 폰트, 이미지, 스타일 로딩은 다음과 같이 작성합니다. 폰트, 이미지, 스타일 로딩은 브라우저에서 서버로 보내는 요청을 중간에 방해한다는 것을 메서드명 .setRequestInterception()을 보면 알 수 있습니다.
await page.setRequestInterception(true);
await page.on('request', req => {
if (
req.resourceType() == 'stylesheet' ||
req.resourceType() == 'font' ||
req.resourceType() == 'image'
) {
req.abort();
} else {
req.continue();
}
});
await page.setJavaScriptEnabled(false);
위에서 언급한 옵션들은 개발 중에 활성화하고 개발할 시에 크롤이 제대로 되지 않는 경우들을 접할 수 있습니다. 그러니 개발이 끝난 후 성능 향상을 위한 목적으로 사용하시길 바라겠습니다.
여기서 언급하지 않은 옵션들은 공식문서에서 확인하실 수 있습니다.
다음편부터는 본격적으로 코드를 짜면서 이야기하도록 하겠습니다. 페이지네이션 형태는 뽐뿌를, 무한스크롤 형태는 인스타그램을 크롤하도록 하겠습니다.